什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种提升大模型回答准确性和减少幻觉的技术,旨在通过结合用户自己的数据,提升大语言模型(LLM)的回答质量和相关性。
约一千三百字·读约四分钟 · English
引言
RAG(Retrieval-Augmented Generation,检索增强生成)是一种提升大模型回答准确性和减少幻觉的技术,旨在通过结合用户自己的数据,提升大语言模型(LLM)的回答质量和相关性。传统AI模型依赖于训练时的静态数据,可能无法提供最新的或特定领域的准确信息。
什么是RAG?
RAG,全称Retrieval-Augmented Generation(检索增强生成),是一种让AI模型结合你自己的数据来回答问题的技术。想象它像一个聪明的助手,能随时查阅你的文档或数据库,确保答案准确且贴合你的需求。
RAG的核心概念
| 概念 | 解释 |
|---|---|
| RAG(检索增强生成) | 使用用户数据与大语言模型结合,通过搜索相关信息来回答问题,而不是仅依赖训练数据。 |
| 索引(Indexing) | 将内容(如文档、wiki)分割成小块,转换为向量(嵌入),存入向量数据库。 |
| 检索(Retrieval) | 将用户问题转换为向量,从数据库中找到最相关的片段。 |
| 生成(Generation) | 将检索到的内容和用户问题组合成提示,输入LLM生成回答。 |
| 优点 | 提供准确、及时的答案;控制信息来源;减少“幻觉”;无需模型重新训练。 |
| 应用场景 | 内部知识助手、客服聊天机器人、企业文档搜索。 |
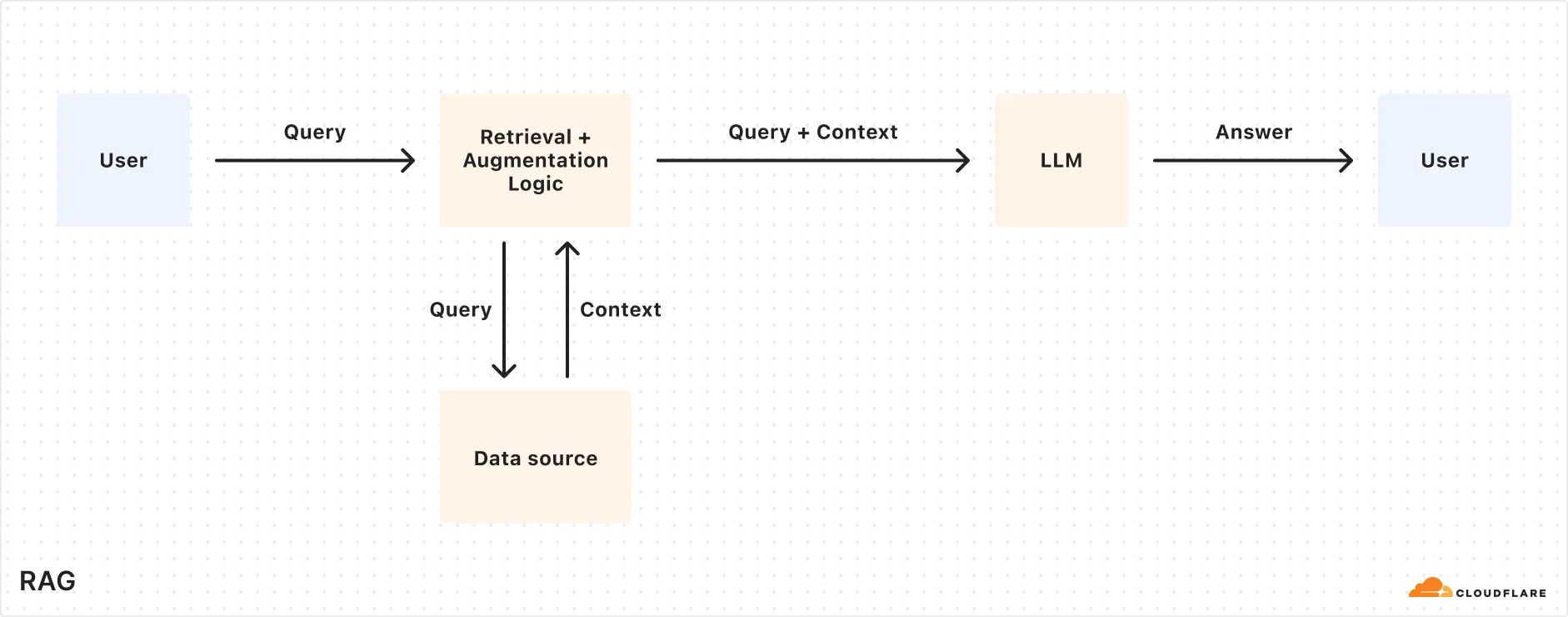
RAG的工作原理
RAG的工作可以分为三个步骤,类比于人类查找信息的过程:
-
准备数据(索引)
想象你有一座巨大的图书馆,里面存放着你的所有文档和信息。RAG会先把这些内容分割成小块,比如把一篇长文档分成段落。然后,它用一种特殊的“编码”方式(叫作嵌入)来表示这些小块。这种编码就像给每段内容贴上标签,标签上写着“这个内容讲的是什么”。这些标签会被存入一个叫作向量数据库的特殊库里,这个库设计用来快速查找相似的内容。 -
查找信息(检索)
当你问AI一个问题,比如“公司今年的假期政策是什么?”AI会先把你的问题也转换为同样的“编码”形式。然后,它会去向量数据库里找那些与你的问题最相似的内容块。这些内容块就是最有可能帮助回答你问题的信息。 -
生成答案(生成)
找到相关信息后,AI会把这些信息和你的原始问题一起输入到大语言模型中。大语言模型就像一个聪明的学生,它会根据这些信息和问题,生成一个完整的、符合逻辑的回答。类比于人类,AI就像在考试时先翻阅笔记,然后用自己的话总结答案。
这一流程确保了AI的回答不仅基于其训练知识,还结合了最新的、特定领域的信息。
RAG的优点
RAG有几个显著的优势:
- 准确性和及时性:AI的回答基于用户上传的最新数据,而不是依赖可能过时的训练数据。这对于需要实时信息的场景尤为重要。
- 信息控制:用户可以决定AI能访问哪些数据,确保答案符合隐私和安全需求。
- 减少“幻觉”:AI有时会“编造”信息(称为幻觉),但RAG通过引用真实数据,可以大大降低这种风险。
- 无需重新训练:传统AI模型在数据更新时需要重新训练,耗时且成本高。RAG只需更新数据库,无需调整模型。
这些优点使得RAG在实际应用中表现出色,尤其是在需要高准确度和实时性的场景。
RAG的应用场景
RAG的实际应用涵盖多个领域,以下是几个典型案例:
- 内部知识助手:在大型组织中,员工可以问AI关于公司政策、流程或其他内部信息。例如,员工Alice想知道今年剩余的假期天数,AI会从HR文件中检索她的具体情况,生成准确答案
- 客服聊天机器人:客服机器人可以使用RAG访问最新的产品信息、用户手册或故障排除步骤,为客户提供及时帮助。
- 企业搜索:在大量文档或文件中搜索时,RAG不仅能找到相关文档,还能提供总结或对话式的回答,提升搜索效率。
这些场景展示了RAG如何在实际中提升AI的实用性。
总结
RAG是一种增强检索技术,通过结合用户数据,提升了大语言模型的准确性和实用性。它的工作原理简单易懂,优点显著,应用场景广泛。无论是公司内部知识管理,还是客服支持,RAG都能让AI变得更聪明、更贴合实际需求。
Mttao GitHub ↗
探索技术与生活的智慧