llm · · 4 min read
Chunking Strategies in RAG Systems
Retrieval-Augmented Generation (RAG) has become a key technology in the field of artificial intelligence, enhancing the output quality of large language models by incorporating external knowledge bases. In RAG systems, document chunking strategies are seemingly simple yet crucial components that directly impact retrieval accuracy and overall system efficiency. This article explores how various chunking strategies work, their advantages and disadvantages, and suitable application scenarios to help you choose the best solution for specific use cases.

Retrieval-Augmented Generation (RAG) has become a key technology in the field of artificial intelligence, enhancing the output quality of large language models by incorporating external knowledge bases. In RAG systems, document chunking strategies are seemingly simple yet crucial components that directly impact retrieval accuracy and overall system efficiency. This article explores how various chunking strategies work, their advantages and disadvantages, and suitable application scenarios to help you choose the best solution for specific use cases.
Why is Chunking So Important?
Even as LLM context windows continue to expand, efficient chunking strategies remain essential for several reasons:
- Overcoming Token Limitations: Breaking text into segments that fit within model processing capabilities
- Improving Retrieval Precision: Easier location of information highly relevant to queries
- Reducing Computational Costs: Minimizing the overhead of processing unnecessarily large contexts
- Increasing Signal-to-Noise Ratio: Filtering irrelevant content to provide more refined information
Core Chunking Strategies Explained
1. Fixed-Size Chunking
 How It Works: Divides text into uniform-sized segments based on predefined character count, word count, or token count.
How It Works: Divides text into uniform-sized segments based on predefined character count, word count, or token count.
Advantages:
- Simple and straightforward implementation
- Uniform, controllable size
- Strong versatility with no special dependencies
Disadvantages:
- May break in the middle of sentences or paragraphs
- Doesn’t consider document structure or semantics
Suitable Scenarios: Documents with uniform structure, standardized datasets, user-generated content
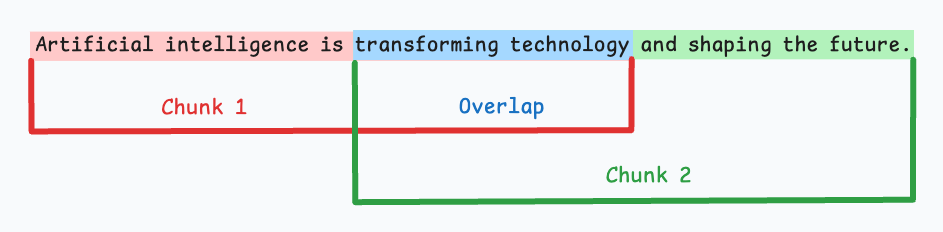
2. Overlapping Chunking Technique
How It Works: Shares a certain percentage of content between consecutive text blocks (typically 10-20% of block size).
Advantages:
- Reduces boundary information loss
- Improves contextual continuity
- Enhances retrieval accuracy
Disadvantages:
- Data redundancy
- Increases storage and computational burden
Suitable Scenarios: Used in combination with fixed-size chunking, especially suitable for conversation records with frequent speaker changes
3. Recursive Chunking
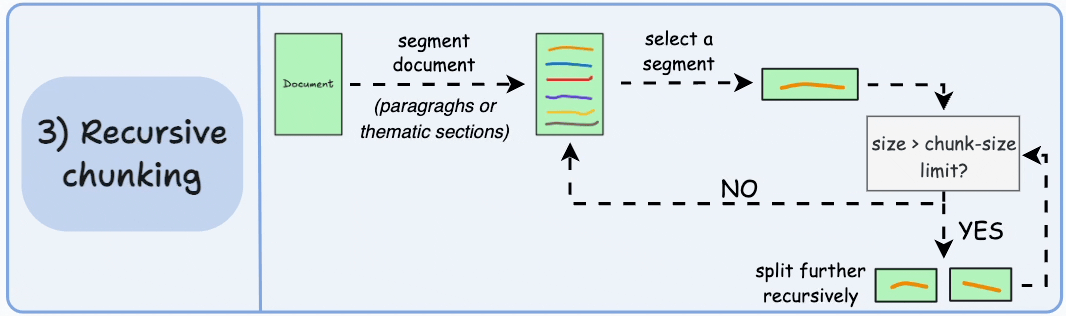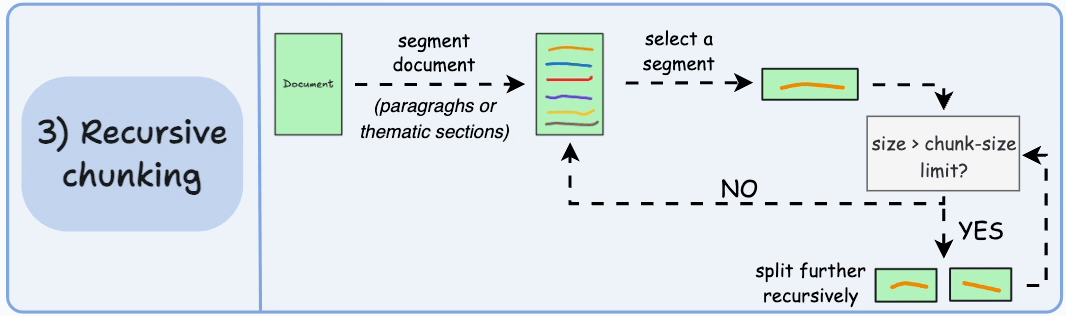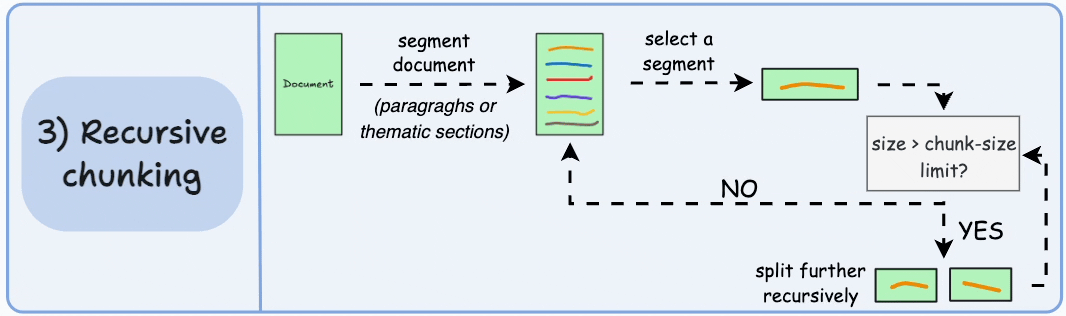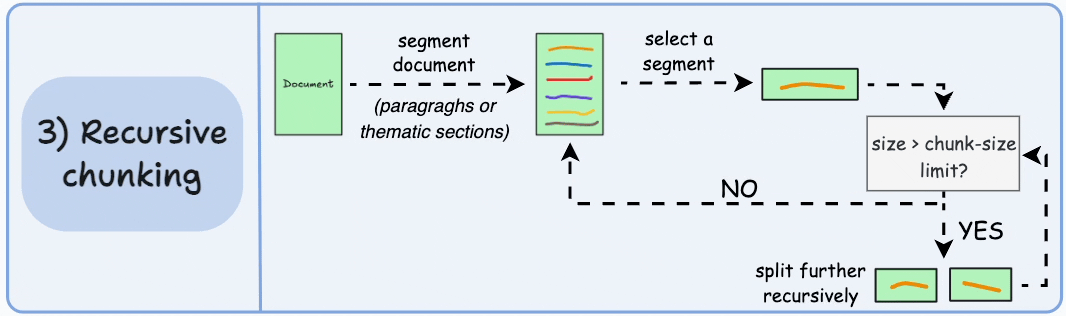 **How It Works**: Recursively splits text using hierarchical separators (such as paragraph markers \n\n, sentence markers \n, spaces).
**How It Works**: Recursively splits text using hierarchical separators (such as paragraph markers \n\n, sentence markers \n, spaces).
Advantages:
- Better preserves text structure and semantics
- Highly adaptable, accommodating various data types
- Reduces text fragmentation
Disadvantages:
- Potentially slower processing speed
- Cannot guarantee strictly consistent block sizes
- Higher computational complexity
Suitable Scenarios: Plain text documents, hierarchical text, cases requiring preservation of document structure
4. Document-Specific Chunking
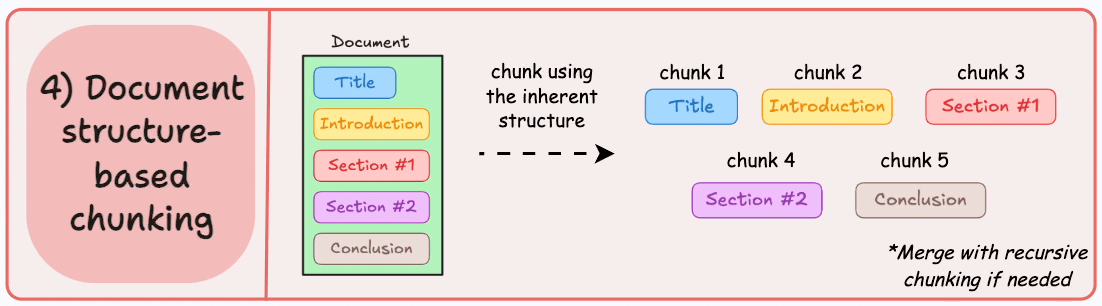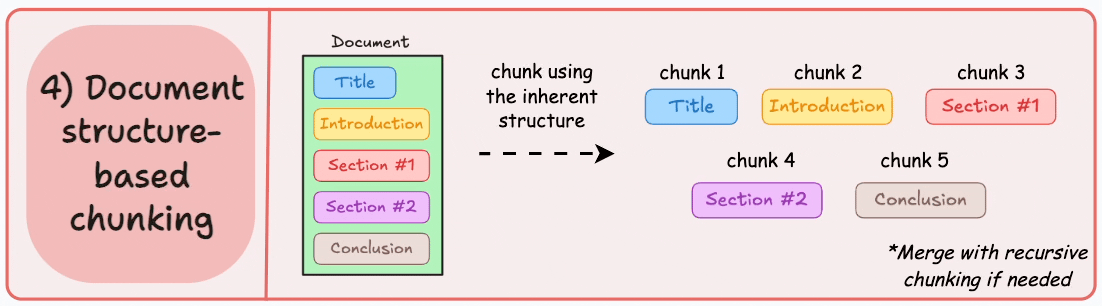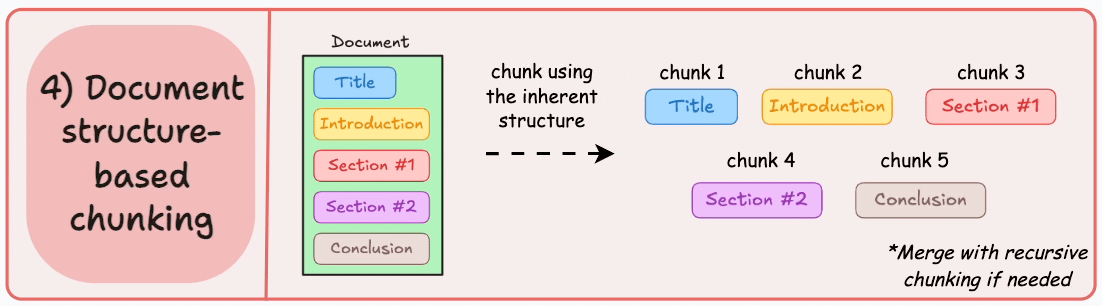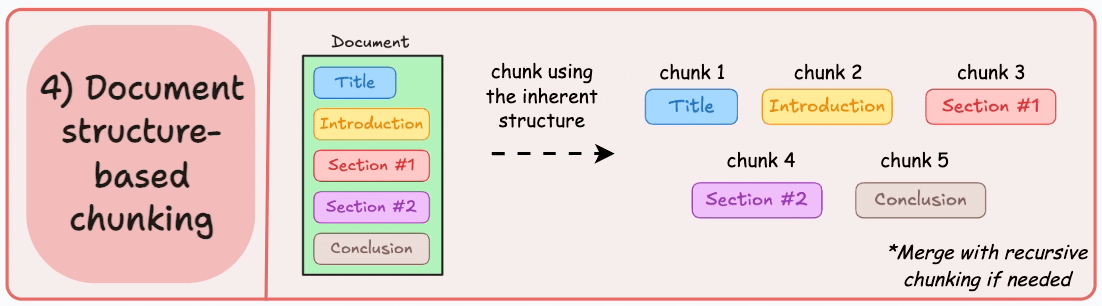
How It Works: Utilizes the inherent logical structure of documents (headings, paragraphs, sections, etc.) for chunking.
Advantages:
- Maintains author intent and logical flow
- High contextual relevance
- Better preserves semantic integrity
Disadvantages:
- Highly dependent on document structure clarity
- Complex implementation, requiring specific parsers for different formats
- Limited effectiveness for unstructured text
Suitable Scenarios: Technical manuals, research papers, legal documents, code documentation
5. Semantic Chunking
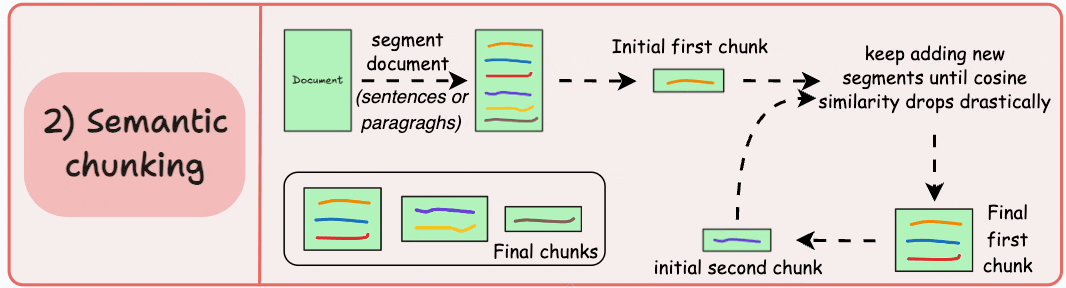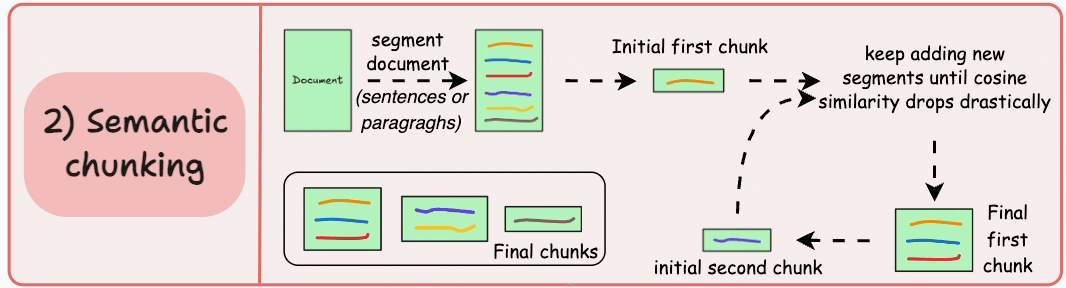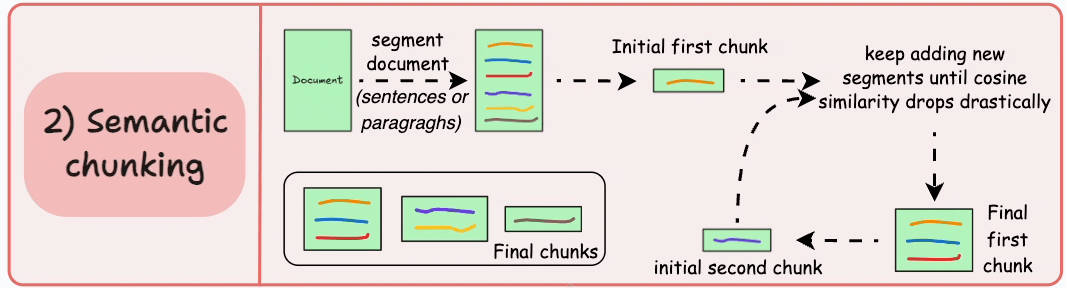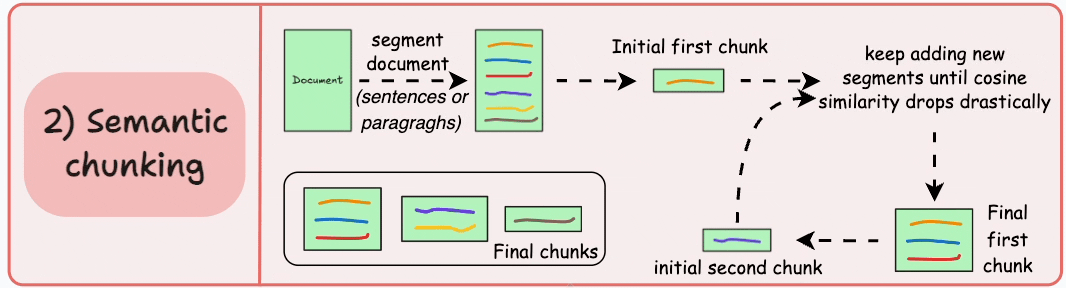 **How It Works**: Groups text based on semantic similarity of sentences or text fragments, identifying topic transition points.
**How It Works**: Groups text based on semantic similarity of sentences or text fragments, identifying topic transition points.
Advantages:
- High retrieval quality
- Each chunk represents a complete concept
- Avoids embedding multiple meanings in a single vector
Disadvantages:
- High computational cost
- Requires embedding models and similarity calculations
- Complex parameter tuning
Suitable Scenarios: Legal document analysis, medical research, tasks requiring high contextual accuracy
6. Hybrid Chunking
How It Works: Combines multiple chunking techniques to leverage their respective advantages while mitigating limitations.
Advantages:
- Highly adaptable and customizable
- Improves contextual embedding
- Potentially higher accuracy
Disadvantages:
- Complex design and implementation
- Higher computational cost
- Difficult optimization
Suitable Scenarios: Complex heterogeneous documents, applications with extremely high accuracy requirements
How to Choose the Most Appropriate Chunking Strategy?
Selecting a suitable chunking strategy requires consideration of multiple factors:
-
Document Type and Structure
- Structured content is suited for document-specific chunking
- Unstructured content benefits from recursive or semantic chunking
-
Query Type and Task
- Specific fact queries need fine-grained chunking
- Thematic queries work better with chunks aligned to document sections
-
LLM Token Limits and Resource Constraints
- Ensure chunk size complies with model processing capabilities
- Balance computational resources against chunking complexity
-
Context Preservation and Granularity Balance
- Small chunks provide precision but may lose context
- Large chunks maintain context but may exceed limits
Practical Recommendations
- Start Simple: Begin with recursive chunking with overlap to establish a baseline
- Understand Your Data Deeply: Analyze document types, structure, and content modality
- Continuously Evaluate and Optimize: Test different parameter combinations and monitor performance metrics
- Don’t Ignore Overlap: Overlap parameter adjustment is crucial, especially for fixed-size chunking
- Balance Cost and Benefit: Advanced strategies may improve performance but increase computational overhead
Future Outlook
RAG continues to evolve rapidly, with noteworthy trends including:
- Agent-Based Chunking: Using LLMs to determine how documents should be divided
- Context-Enhanced Chunking: Adding summaries of previous chunks to current chunks
- Multimodal Chunking: Processing relationships between text and other modal data
- Graph-Based Chunking: Using graph databases to store relationships between chunks
Conclusion
Document chunking appears simple but involves complex trade-offs requiring deep understanding, careful design, and repeated experimentation. As RAG systems become more widespread, efficient chunking strategies will continue to play a critical role in helping models generate higher quality, fact-based responses that are highly relevant to user needs.
There is no one-size-fits-all optimal chunking approach. What matters is selecting appropriate strategies based on specific scenarios, finding the ideal balance between contextual integrity, retrieval precision, and computational efficiency.
Mttao GitHub ↗
Exploring technology and life's wisdom